AI Resource Finder Tool
Trouvez les meilleures ressources sur l'intelligence artificielle pour apprendre en quelques secondes.
Fonctionnalités : Ressources
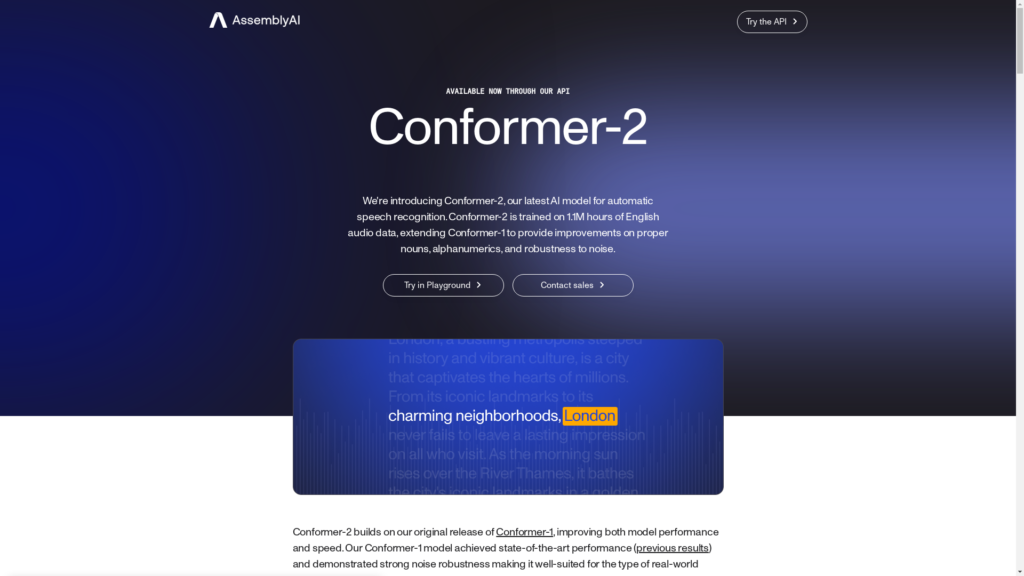
Le modèle d’IA à la pointe Conformer-2 est spécifiquement conçu pour la reconnaissance automatique de la parole (ASR). En se basant sur le succès de son prédécesseur, le Conformer-1, ce modèle avancé a été entraîné sur un ensemble de données étendu de 1,1 million d’heures audio en anglais, ce qui a conduit à des améliorations remarquables dans divers aspects de la reconnaissance vocale.
Le développement du Conformer-2 a été guidé par les lois d’échelle proposées dans l’article Chinchilla de DeepMind. Comprendre l’importance des données d’entraînement suffisantes pour les grands modèles linguistiques, le Conformer-2 exploite un immense ensemble de données audio en anglais représentant 1,1 million d’heures pendant son processus d’entraînement.
L’une des fonctionnalités phares du Conformer-2 est son adoption de la technique d’ensemblement de modèles. Au lieu de s’appuyer sur les prédictions d’un seul modèle enseignant, le Conformer-2 génère des étiquettes à partir de plusieurs modèles enseignants solides. Cette technique d’ensemblement réduit la variance et améliore les performances du modèle lorsqu’il traite des données non vues auparavant pendant l’entraînement.
Malgré une taille accrue du modèle, le Conformer-2 présente des améliorations en termes de vitesse par rapport au Conformer-1. L’infrastructure de service a été optimisée méticuleusement, ce qui se traduit par des temps de traitement plus rapides. Le Conformer-2 permet d’obtenir une réduction allant jusqu’à 55% de la durée de traitement relative pour toutes les durées de fichiers audio.
Le modèle Conformer-2 s’avère être un composant inestimable pour les pipelines d’IA axés sur les applications d’IA générative utilisant des données vocales. Ses capacités remarquables de transcription parole-texte en font un outil précieux pour générer des transcriptions précises avec une précision et une fiabilité exceptionnelles.
Dans les applications du monde réel, le Conformer-2 démontre des améliorations significatives dans diverses métriques axées sur l’utilisateur. Il réalise notamment une amélioration de 31,7% sur les alphanumériques, une amélioration de 6,8% sur le taux d’erreur des noms propres et une amélioration de 12,0% en termes de robustesse au bruit. Ces améliorations sont attribuées tant aux vastes données d’entraînement qu’à l’utilisation d’un ensemble de modèles.
Catégories : Expériences, Ressources
Le modèle d’IA à la pointe Conformer-2 est spécifiquement conçu pour la reconnaissance automatique de la parole (ASR). En se basant sur le succès de son prédécesseur, le Conformer-1, ce modèle avancé a été entraîné sur un ensemble de données étendu de 1,1 million d’heures audio en anglais, ce qui a conduit à des améliorations remarquables dans divers aspects de la reconnaissance vocale.
Le développement du Conformer-2 a été guidé par les lois d’échelle proposées dans l’article Chinchilla de DeepMind. Comprendre l’importance des données d’entraînement suffisantes pour les grands modèles linguistiques, le Conformer-2 exploite un immense ensemble de données audio en anglais représentant 1,1 million d’heures pendant son processus d’entraînement.
L’une des fonctionnalités phares du Conformer-2 est son adoption de la technique d’ensemblement de modèles. Au lieu de s’appuyer sur les prédictions d’un seul modèle enseignant, le Conformer-2 génère des étiquettes à partir de plusieurs modèles enseignants solides. Cette technique d’ensemblement réduit la variance et améliore les performances du modèle lorsqu’il traite des données non vues auparavant pendant l’entraînement.
Malgré une taille accrue du modèle, le Conformer-2 présente des améliorations en termes de vitesse par rapport au Conformer-1. L’infrastructure de service a été optimisée méticuleusement, ce qui se traduit par des temps de traitement plus rapides. Le Conformer-2 permet d’obtenir une réduction allant jusqu’à 55% de la durée de traitement relative pour toutes les durées de fichiers audio.
Le modèle Conformer-2 s’avère être un composant inestimable pour les pipelines d’IA axés sur les applications d’IA générative utilisant des données vocales. Ses capacités remarquables de transcription parole-texte en font un outil précieux pour générer des transcriptions précises avec une précision et une fiabilité exceptionnelles.
Dans les applications du monde réel, le Conformer-2 démontre des améliorations significatives dans diverses métriques axées sur l’utilisateur. Il réalise notamment une amélioration de 31,7% sur les alphanumériques, une amélioration de 6,8% sur le taux d’erreur des noms propres et une amélioration de 12,0% en termes de robustesse au bruit. Ces améliorations sont attribuées tant aux vastes données d’entraînement qu’à l’utilisation d’un ensemble de modèles.
Fonctionnalités : Ressources
Fonctionnalités : Art, Ressources

Fonctionnalités : Expériences
Fonctionnalités : Low-code/no-code, Ressources

Fonctionnalités : Ressources
Fonctionnalités : Ressources
Partager la fiche :